


Using Postman for testing
Postman is a collaboration platform for API development and testing. Postman's features simplify each step of building an API and streamline collaboration, so you can create better APIs faster. We recommend downloading Postman for a quick and easy API exploration.
Postman provides an excellent start to experience the ON!Track API in the following domains:
- API Client: Quickly and easily send REST, SOAP, and GraphQL requests directly within Postman
- Automated Testing: Automate manual tests and integrate them into your CI/CD pipeline to ensure that any code changes won't break the API in production
- Design & Mock: Communicate the expected behavior of an API by simulating endpoints and their responses without having to set up a backend server
- Documentation: Generate and publish beautiful, machine-readable documentation to make APIs easier to consume
- Monitor: Stay up-to-date on the health of the API by checking performance and response times at scheduled intervals
Create an authentication request in Postman
The following information, needed to be authenticated when making API calls, are sent by email:
- Client ID
- Client Secret
- Username of the technical user
- Password of the technical user
The following procedure explains how to get the API access token, once you possess the aforementioned credentials:
- Open and launch Postman, create a new workspace, and add a new collection for your API calls by clicking on "+"
- Select request method "POST" and enter the following request URL for the call to retrieve an access token:
URL for the post call to get the access token:
https://cloudsso.hilti.com/hc/token
- Select the "Authorization" tab and set Type to "Basic Auth". Enter the "Client ID" and "Client Secret" into respectively, the "Username" and "Password" fields.

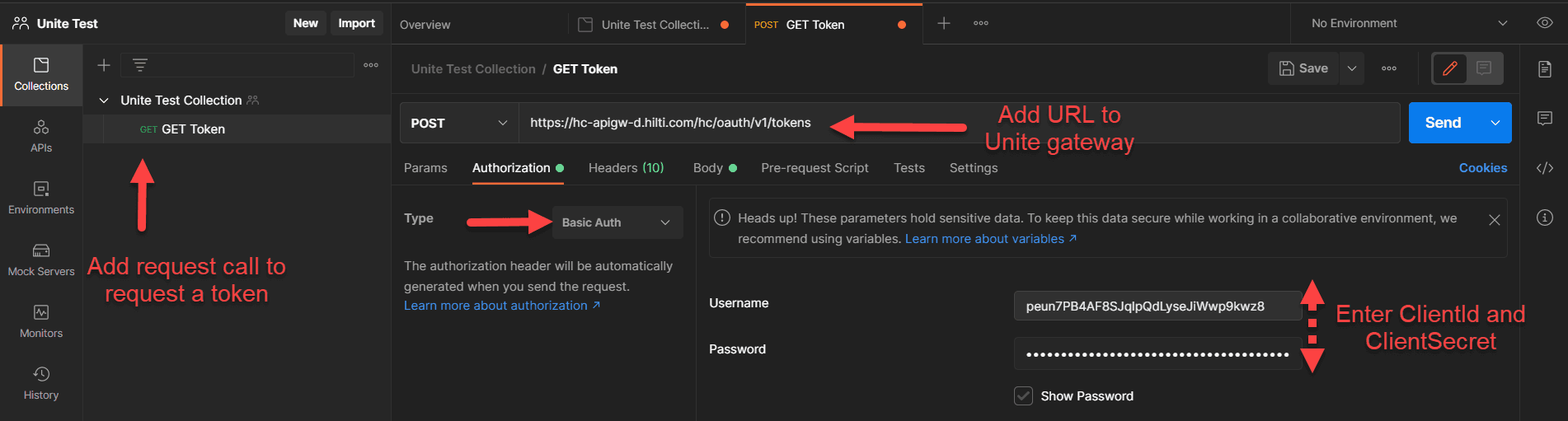
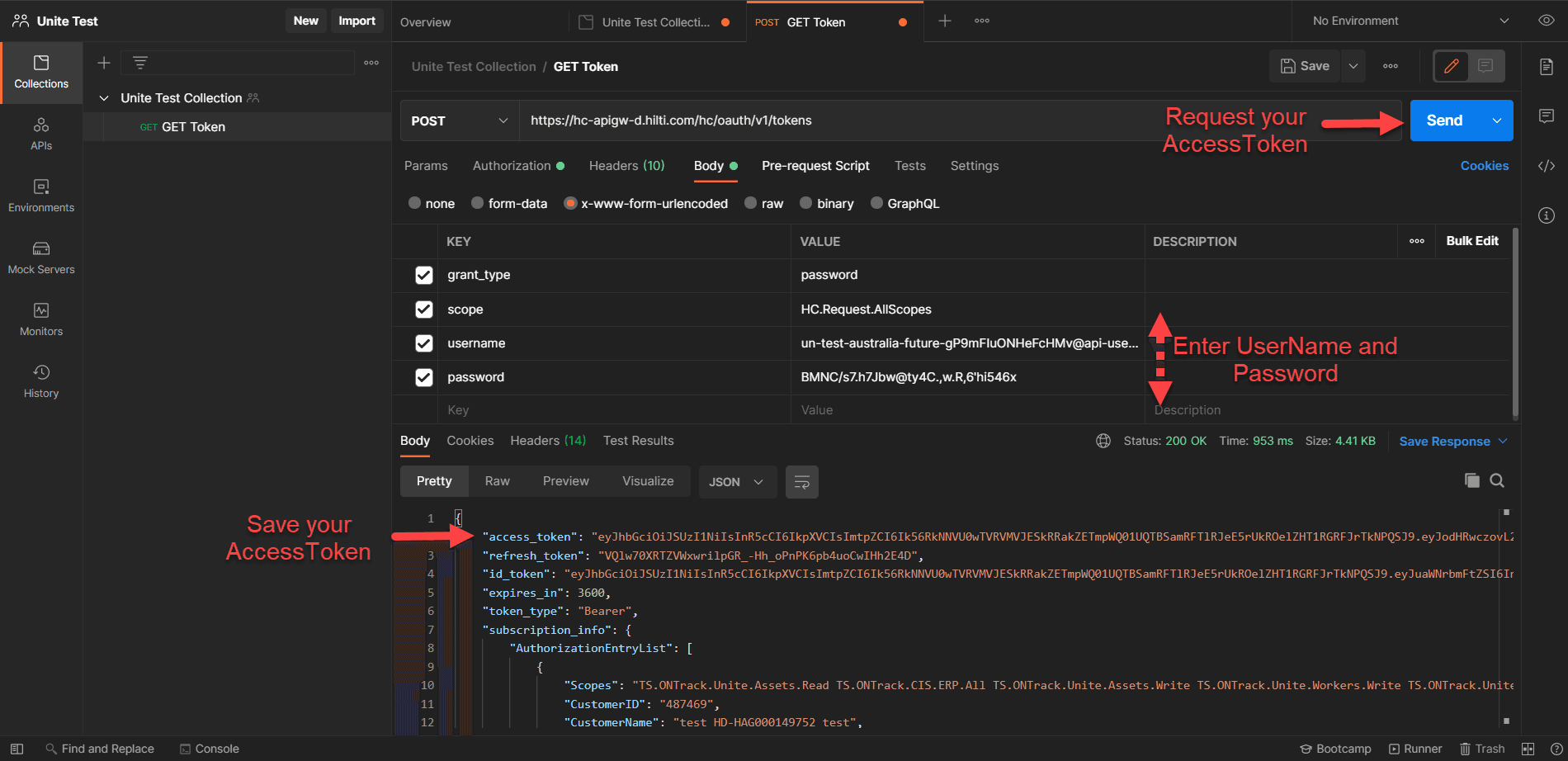
- Select the "Body" tab, pick "x-www-form-urlencoded" and add the following data:
| Key | Value |
|---|---|
| grant_type | password |
| username | Username of technical user |
| password | Password of technical user |
- Hit "Send", receive your access token and store it in your IDE (for that, make sure you have selected the right environment, see top right of the Postman screen)

Token lifecycle
The token lifecycle is designed the following way:
- Get a new access token
- The token remains valid for 60 min
- Cache the token and do not request a new one for each API call
- After the token expires request a new token
Make your first API call with Postman
Follow the three simple steps to get started with ON!Track Unite and make the first data sync:
- Request and get via email the credentials of the technical user
- Download the ON!Track Unite Software Development Kit for Postman (see above)
- Import the Postman collection and environment, authenticate and fire your first API calls:
- Import your collection (part of the downloaded SDK)
- Import your environment (part of the downloaded SDK)
- Set your credentials and get authenticated (see chapter above)
- Create your first data objects in ON!Track (e.g. a Worker, Location, and Asset) with the relevant API calls
- Login to your ON!Track WEB UI and transfer at least an Asset from one location to another
- Use the Transfer API to read out from ON!Track the transfer details
https://cloudapis.hilti.com/ts/ontrack/unite/v1/entity
Data preparation and mapping
In this chapter, we describe how the data in ON!Track and in the external application shall be prepared for the integration to work and how to correctly map the data in the connector. It is a good idea to browse through the Guides as well as read thoroughly the API specification to get a quick start in the business object provided by ON!Track. It is also very important to correctly match the business object between the external application and ON!Track.
The three following chapters cover different initial situations, which differ based on whether data are already present in ON!Track and in the external system. In the following description, we refer to "items" as workers, locations, assets, and quantity items.
Scenario 1 - ON!Track account is empty
This scenario is valid in case of a completely empty ON!Track account (for example in case of a new implementation) or for new items that are not yet registered in ON!Track but available in the external system (e.g. an ERP).
- Create workers, locations, and assets in ON!Track based on the data already available in the external system
- To ensure that the items are correctly matched between ON!Track and the external system, make sure to add an external ID for each item during the creation process (typically the external ID is the unique identifier used in the external system)
- After an item is created in ON!Track, a unique ON!Track item ID is created and can be read with a GET call that shall be stored in your solution to match ON!Track objects
Scenario 2 - External system account is empty
This scenario is valid in case of a completely empty external system, or for new items that are not yet registered in the external system but available in ON!Track. As ON!Track already stores valuable data for external systems, this data can be extracted and added in the external systems.
- Get a list of workers, locations, and assets from ON!Track by the relevant list API operations
- Add workers, locations, and assets in the external system and enrich them with unique IDs
- The unique ON!Track item ID that shall be stored in the external system to correctly match the corresponding ON!Track item
- Merge by writing the external ID of these items by POST operation to ON!Track (typically the external ID is the unique identifier used in the external system)
Scenario 3 - Both ON!Track and the external system are in place
In this case, a set of items is co-existing both in ON!Track and in the external system. To make sure no duplicates are created, we recommend this process that leverages unique identifiers:
- Get a list of all workers, locations, and assets from ON!Track by the list operation
- Get a list of all workers, locations, and assets from the external system
- Compare the lists and match the same objects with common identifiers, that are typical for that object (e.g. a worker can be matched by the same ID, name, surname, phone, address, etc.)
- Update objects where matches are possible
- Merge by writing the external IDs, by POST operation to ON!Track
- The external system can provide an optional exclusion list for all items, that should not be synced
- Create offset of objects that could not be merged for manual check for the end customer
Data editing workflows
When using ON!Track integrated with an external application, it is very important to keep in mind the master/slave relation between the two systems, i.e. the direction in which the data flows between ON!Track and the external system. As a general rule, when ON!Track is the master for a given item, all data shall be written and edited in ON!Track and these are automatically reflected in the external system via API or vice-versa when the external system is the master. There are however cases when some data fields are edited in the slave system and shall be considered carefully to avoid potential data losses.
Correct implementation of the connector To avoid that data typed in ON!Track is canceled or overwritten by data coming from the external system, it is suggested to implement a business logic in the connector that correctly addresses the master/slave relation for the editing workflows. That is, always perform a comparison of the data present in the external system and ON!Track and only edit (PUT API call) the relevant data fields.The correct implementation of the connector is especially relevant for data that are manually entered in ON!Track, but the relative data field in the external system is empty. In this case, the business logic shall be implemented in such a way that "null" data fields coming from the external system do not overwrite the ON!Track data.
To implement the correct editing workflow when ON!Track is the slave system, we suggest the following procedure:
- With a POST call, create an item in ON!Track from the external system
- A user manually edits the items details in the ON!Track application
- The connector performs a GET call to read out from ON!Track the item details
- The connector compares the data got from ON!Track in point 3. with the ones coming from the external system
- In all those cases where data is added in ON!Track, and the respective data field is "null" in the external system, the connector shall use the data read from ON!Track in point 3 for the PUT call
Consider the following example of an incorrect implementation:
- A new asset is created from the external system in ON!Track, but the asset scancode is not present in the external system
- The user adds the scancode in ON!Track
- As there is no business logic implemented when the two applications next sync the scancode is canceled from ON!Track
The correct implementation of the connector is described with the following example:
- A new asset is created from the external system in ON!Track, but the asset scancode is not present in the external system
- The user add the scancode in ON!Track
- The connector performs a GET call to get the asset details from ON!Track and compare it with the same asset data from the external system, with these operations the connector realizes that the asset scancode was entered in ON!Track
- The scancode is either written back in the external system, or that data field excluded from the following PUT calls for that asset
- The asset scancode is correctly kept in ON!Track and possibly written back in the external system
If no business logic for editing is implemented in the connector, consider the following example as a reference of how the data shall be correctly entered:
- An ERP is the leading system for workers data and ON!Track the slave
- A new worker, "Tom", is manually created in the ERP, and that automatically triggers the creation of the worker "Tom" in ON!Track
- An ON!Track user sees a mistake with the worker and edits that in ON!Track (changed "Tom" to "Thomas")
- The name is not edited in the master i.e. in the ERP the name is still "Tom"
- When the next data sync between the ERP and ON!Track happens, in the name of the worker in ON!Track is edited from "Thomas" back to "Tom"
- The correct behavior is to edit the name directly in the ERP instead of in ON!Track (point 3.)
Testing the integration workflows
General test cases
To test that the integration was successfully coded, we recommend to perform these high-level steps:
- Create workers, locations, and assets in ON!Track (in this order), with special attention to Hilti assets and on how standard codes are utilized (country, states, languages, and currencies)
- Read the transfer data out from ON!Track
- Read Asset Usage Condition from ON!Track
- Update workers, locations, and assets in ON!Track leveraging the ON!Track ID and make sure that no data are lost during the editing workflow
Special test cases
Standard asset with template
- Create an asset with both model and manufacturer and assign it to a default employee (can be a standard user) and default location (can be a warehouse)
- Update the same asset (no possibility to edit the fields controlled by the asset template, such as asset model and manufacturer)
- Repeat the same for assets with Hilti as the manufacturer to check the correct behavior (reference to guides)
Standard asset without template
- Create an asset with either model or manufacturer and assign it to a default employee (can be a standard user) and default location (can be a warehouse)
- Update the same asset (all data fields shall be editable)
Transfers Try the following transfer, to check the implications in the external system:
- Warehouse to warehouse
- Warehouse to Jobsite
- Jobsite to Warehouse
- Jobsite to Jobsite
- Warehouse to employee to jobsite
- Jobsite to employee to warehouse
- Warehouse to employee to warehouse
- Jobsite to employee to jobsite